

How does Hypothesis Testing work?
How does it work? Well, think for a moment about a jury trial. The defendant is firstly presumed innocent. Facts and evidence are presented before the court. The jury then decides if it is unlikely, beyond a reasonable doubt, that the defendant is innocent. If they decide that it is unlikely that the defendant is innocent, then they declare that the defendant is guilty. If they decide that there is not enough evidence to convince them that the defendant is guilty, then they declare that they find the defendant not guilty. We do not know if the defendant is truly guilty or innocent and so there are four possible outcomes, as can be seen in the following diagram.

Clearly, we would like to see as few innocent people as possible going to jail and we would also like to prevent criminals going free as much as possible. This requires us to have some kind of trade-off between being too lenient and being too strict with the level of evidence required to reject the assumption of innocence.
Hypothesis testing works in a similar manner. We start by assuming that the Null Hypothesis is true. The sample data provides the evidence. We then determine if it is unlikely, beyond some preset level, that the Null Hypothesis is true. If we decide that it is unlikely that the Null Hypothesis is true, we declare that we "reject the Null Hypothesis". If we decide that there is not enough evidence, then we declare that we "fail to reject the Null Hypothesis". Again, we do not know the truth about the Null Hypothesis; we can only make an inference based on the sample data.
In hypothesis testing, we ASSUME that the Null Hypothesis (or the hypothesis of no change) is true.
More formally, we examine the evidence and determine the probability of obtaining our result or one more extreme under the assumption that the Null Hypothesis is true, i.e. 
Null Hypothesis Significance Testing, regardless of the test statistic used (e.g. 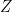
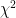


- State the hypotheses, significance level (
), any assumptions/definitions
- Based upon the sample data, compute an appropriate decision statistic
- Reject or Fail to Reject the Null Hypothesis. State your conclusion.
- Where appropriate, conduct a suitable Post-Hoc test and interpret it
Depending on your discipline or the journal you intend to publish with, you may also be required to compute and state other items like an estimate of the Effect Size. Your lecturers, tutors, supervisors or journal editors will be able to provide you with a better guide as to what else you may be required to do whenever you conduct a Hypothesis test; however, the steps above are reasonably close to universal, despite what some textbooks may say.
Just like in the jury trial, there are four possible outcomes depending on the true situation and the decision we make in the test. The following illustrates these possible outcomes.

Let’s take a closer look at each of these steps.
State the hypotheses, significance level (), any assumptions/definitions
Hypotheses
The hypotheses are the Null and Alternate hypotheses. A Hypothesis is a definitive statement about a population parameter in present or past tense taken from the research question. Typically, there are two hypotheses (see note 1), one of which is called the Null Hypothesis (denoted by 

The Alternate Hypothesis can also indicate the direction of interest, for example, if we are testing the fuel additive and the effect on emissions, we most likely don’t want to use the additive if it makes emissions worse. In such a case, the Alternative Hypothesis may state that population parameter is less than (or greater than) the specified value. Such alternative hypotheses are often referred to as a directional hypothesis. Typically, however, it is preferable to use a non-directional Alternate Hypothesis and determine the direction of any change after completing the hypothesis test. The following table shows the three possible sets of hypotheses for the population mean (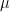
| Non-directional | Directional | ||
| (two-tailed) | (one-tailed, lower) | (one-tailed, upper) | |
| Null Hypothesis | :  |
: |
: |
| Alternate Hypothesis | :  |
:  |
:  |
Note: the symbol 


Significance level
The significance level (denoted by 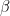
Similar to how 
In general, non-life threatening research we typically set our significance level to 5% (i.e. 


Assumptions and definitions
All hypothesis tests have at least two assumptions behind them and depending on which test statistic you need to compute (e.g.
The second assumption of almost every hypothesis test is what is called the Independence assumption and states that it is assumed that each of the samples are independent of one another. To check that this assumption has not been violated, again you should look closely at the Research Design to see how the samples were obtained. Independence means, in statistical terms, that for any two events, knowing that one event has occurred does not influence the probability of the other event occurring, i.e. the conditional probability of each event is equal to its unconditional probability (

The last part of this step is to define any terms used or special symbols. For example, if you are conducting a hypothesis test using patient BDI scores, you need to define what a BDI score is. Alternatively, you might be conducting a hypothesis test comparing males and females, and so it is important to identify for your reader which symbol(s) represent the variables for males and which represent the variables for females. There is no need to state a definition for 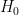
Based upon the sample data, compute an appropriate decision statistic
There are three types of decision statistic methods that can be used, namely:
- The Critical Value method
- The p-value method
- The Confidence Interval method
The choice of decision statistic method greatly depends on the kind of statistical test you are performing and the reporting requirements of your discipline. In most cases, however, the Confidence Interval method is preferred over the p-value method. The Critical value method should only be used as a last resort as it provides the least amount of information to your reader.
The Critical Value method
The Critical Value method is the simplest method for a making a decision. Under this method, we find the critical value(s) under the Null Hypothesis distribution that represents the cut-off point(s) for the rejection region. If we are conducting a non-directional hypothesis test (i.e. two-tailed test), then we need two critical values, each cutting off 
| Non-directional | Directional | ||
| (two-tailed) | (one-tailed, lower) | (one-tailed, upper) | |
| Null Hypothesis | : |
: |
: |
| Alternate Hypothesis | : |
: |
: |
| Critical Value(s) |  |
 |
 |
| Graphically |  |
 |
 |
The p-value method
This decision method is more informative to your reader than the critical value method and tends to dominate the research literature in most disciplines at present. Under this method, the Significance Level (

This probability is what we call our p-value. This is a conditional probability, not the probability that the Null Hypothesis is true. In fact, as is seen in the conditional probability above, in hypothesis testing we assume that the Null Hypothesis is true, so 
This might get you thinking that hypothesis testing is a waste of time since we really want to know what is the probability that the Null Hypothesis is true. Hypothesis testing is certainly not a waste of time; rather we have to recognise the limitations of what hypothesis testing can do and be careful in our interpretations (see Ovens (2018) for some common misconceptions).
By way of comparison, we know that jury trials are not perfect and we recognise that sometimes an innocent person goes to jail or a criminal walks free. Jury trials also presume that the defendant is innocent at the start of the trial, the evidence is presented, and the jury tries to figure out 


So the p-value is a conditional probability, namely the probability of obtaining this test statistic or one more extreme under the Null Hypothesis distribution, but what is the test statistic? Well, that depends on the form of hypothesis test you are doing, in general; however, most test-statistics have the following form:

To help illustrate the p-value method, the figure below shows a two-tailed hypothesis test where the Null Hypothesis distribution is a Standard Normal distribution with 


The Confidence Interval method
Like the test statistic in the p-value method, this method depends on the hypothesis test you are performing, and in some cases, you would be very unlikely to compute the Confidence Interval. The general form, however, of a Confidence Interval is:

Where the Margin of Error is given by:

Note: the "Standard Error term" is the term representing the "Standard Error of the Sampling Distribution" that is used in calculating the test statistic.
Confidence Intervals are somewhat misnamed. Unfortunately, the word "Confidence" implies some level of certainty or belief in our obtained interval. It is not unusual to see researchers write in their papers, "We are 95% confident that the true population mean is between 123.6 and 127.8", when what they should write is, "We obtain a 95% Confidence Interval for the true population mean of (123.6, 127.8). Ninety-five per cent of intervals obtained in this manner would capture the true population mean." It may not seem obvious to you, but there is a profound difference between these two statements (see this page for more details).
When using the Confidence Interval method, the value of the population parameter of interest under the Null Hypothesis acts as our yardstick. Under this method, we look to see if our obtained confidence interval for the population parameter of interest captures the Null Hypothesised value in order to make our decision to either "Reject" or "Fail to Reject" the assumption that the Null Hypothesis is true.
Reject or Fail to Reject the Null Hypothesis. State your conclusion.
Before we make a decision to "Reject" or "Fail to Reject" the assumption that the Null Hypothesis is true, we must understand how the decision statistic was determined. The appropriate decision statistic was determined given the Null Hypothesis is true, so much like in a jury trial, we have to decide if that is enough evidence to reject the assumption that the Null Hypothesis is true. In other words, if the decision statistic is unusual enough for us to conclude that it is unlikely to occur by chance, we conclude that it is unlikely the Null Hypothesis is true and so, therefore, the Null Hypothesis is not supported by the evidence presented by our sample data. For the decision statistic to be "unusual enough" for us to conclude that the Null Hypothesis should be rejected, we use our decision method’s yardstick that we defined at the very beginning of our test: (1) the Critical Value; (2) our Significance Level (
Comparing our obtained Test Statistic to the Critical Value
In this type of decision, we compare our Test Statistic to the Critical Value (in general obtained from a table of the distribution model). If our obtained Test Statistic is more extreme than the Critical Value then we Reject the Null Hypothesis, otherwise, we Fail to Reject the Null Hypothesis. This is the simplest form of decision making for a Hypothesis test.
Comparing our obtained p-value to
Putting it very simply, in this type of decision:
If
we Reject the Null Hypothesis, otherwise, we Fail to Reject the Null Hypothesis (see note 4).
This is the most common form of decision making for a Hypothesis test in the research literature of most disciplines. Most statistical packages, such as R or SPSS will produce a p-value as part of the output for a Hypothesis test.
Noting if our Confidence Interval captures our Null Hypothesis value
This type of decision is becoming more common as researchers begin to appreciate the information a Confidence Interval provides. In this type of decision, we look to see if our obtained Confidence Interval "captures" the Null Hypothesised value of the population parameter. If the Confidence Interval does not capture this value then we Reject the Null Hypothesis, otherwise, we Fail to Reject the Null Hypothesis.
A good way to envisage these forms of decision making is to think about the fence around a property. The fence represents the Critical Value of the test, whilst in this analogy, you will represent the Test Statistic. Suppose you are arrested on suspicion of trespassing (i.e. a sample is taken).
- The judge will ask you which side of the fence did the police catch you on. If you are on the wrong side of the fence you will be found guilty (i.e. Reject the Null Hypothesis) otherwise you will be found not guilty (i.e. Fail to Reject the Null Hypothesis) (decision method 1).
- The judge might also ask how far from the centre of the roadway were you when you were caught to determine the level of evidence that you were not trespassing (i.e. p-value). If the level of evidence that you were not trespassing is very small, the judge will find you guilty (i.e. Reject the Null Hypothesis) otherwise you will be found not guilty (Fail to Reject the Null Hypothesis) (decision method 2).
- The judge might also estimate how fast you could run and guess that when you heard the sirens you started running, meaning that you could have been either much further away from the centre of the roadway or much closer to it when you heard the sirens. If the judge believes that it was not possible for you to be anywhere near the centre of the road, you will be found guilty (Reject the Null Hypothesis). If, however, the judge believes that it was possible you could have simply run across the centre of the roadway, then you will be found not guilty (Fail to Reject the Null Hypothesis) (decision method 3).
Note: There are various terms used for the decision to "Fail to Reject the Null Hypothesis". When textbooks or research literature talk about "Retaining" or "Accepting" the Null Hypothesis, it does not mean that the Null Hypothesis is true, it just means there is not enough evidence in the sample data to Reject the Null Hypothesis. This is just like when a jury concludes that there is not enough evidence to find a defendant "Guilty", so they say that the defendant is "Not Guilty". The jury is not saying that the person is innocent, just that there is not enough evidence to reject the presumption of innocence.
Having made our decision about the Null Hypothesis, we need to state that decision in a way that other readers of our research can understand. In general this will be something like:
If we Reject the Null Hypothesis:
We Reject H0 with Test Statistic = …, p = … and α = ….
If we Fail to Reject the Null Hypothesis:
We Fail to Reject H0 with Test Statistic = …, p = … and α = ….
Once we made our decision about the Null Hypothesis, we need to state what that decision implies about the Alternate Hypothesis. Typically this is something like:
If we Reject the Null Hypothesis:
The sample data provides statistically significant evidence that . . .
If we Fail to Reject the Null Hypothesis:
The sample data does not provide statistically significant evidence that . . .
We use the term statistically significant to distinguish the fact that our result, whilst significant in terms of the statistics, may not be practically significant. For example, we may invent a new drug treatment for headaches that is statistically significantly faster acting than the present best treatment, but it costs more than the present treatment and is only 20 seconds faster than the present treatment. Obviously, it is not much of a practical improvement, and it is unlikely that many people would want to pay more to relieve their headache 20 seconds faster than the present best treatment.
Where appropriate, conduct a suitable Post-Hoc test and interpret it
After you have determined whether or not you should Reject the Null Hypothesis, you may be able to provide your reader with more information by conducting a suitable post-hoc (i.e. "after the fact") test. For example, if you have used the p-value method for your test, it is usually a good idea to also compute a Confidence Interval and report it. Equally, in some forms of hypothesis tests, if you Reject the Null Hypothesis then all you know is that "at least one is different", but not which one(s). A post-hoc test in those cases allows you to identify the one(s) that are different.
Notes
1. In some advanced forms of hypothesis testing it is possible to have more than two hypotheses; however, the research literature usually involves only two for any single test — the paper may have multiple tests though.
2. Some texts will use the notation of 

3. In some cases, you may only wish to test if the parameter has changed in a particular direction. Generally, in this author’s opinion, it is better to test if the value is statistically significantly different from the value under the Null Hypothesis and determine the direction of change post-hoc. This helps to reduce the chance of making a Type I error and also allows you to detect if there has been a statistically significant change in the opposite direction than anticipated which may be a helpful indicator of either experimental error (e.g. scales not calibrated), theoretical error (e.g. assuming the wrong direction) or computational error (e.g. values have the wrong signs or other data entry errors).
4. Your lecturer might state this as "If 
CITE THIS AS:
Ovens, Matthew. “The Logic of Null Hypothesis Significance Testing”. Retrieved from YourStatsGuru.
First published 2018 | Last updated: 2 November 2024